
XC166單片機(jī)的指令流水線存在著不可避免的阻塞現(xiàn)象,MAC單元指令也一樣。盡管在硬件設(shè)計(jì)時(shí)已經(jīng)采用了專用模塊來(lái)減少阻塞,但有些阻塞是不可避免的,從程序優(yōu)化的角度來(lái)說(shuō),可以充分利用指令流水線阻塞現(xiàn)象,通過(guò)重排指令流水線上的指令,消除阻塞,以使得程序的運(yùn)行時(shí)間縮短,從而達(dá)到優(yōu)化的目的。
通常DSP優(yōu)化方法可以分為兩類:一類是與芯片相關(guān)的,另一類是與芯片無(wú)關(guān)的。與芯片無(wú)關(guān)的優(yōu)化方法獨(dú)立于單片機(jī)硬件,適用于所有單片機(jī)及DSP處理器,下面根據(jù)使用XC166單片機(jī)的經(jīng)驗(yàn)總結(jié)一些優(yōu)化DSP程序的方法。
1 通用優(yōu)化方法
1.1 數(shù)據(jù)組處理
數(shù)據(jù)組處理的基本思想是通過(guò)成組的處理數(shù)據(jù),以節(jié)約每次調(diào)用處理子程序所需的附加指令。數(shù)據(jù)組處理可以在C語(yǔ)言或匯編語(yǔ)言程序中實(shí)現(xiàn)。一般而言,對(duì)于開(kāi)發(fā)DSP程序,最常用的程序語(yǔ)言為C和匯編。下面分別介紹如何在C和匯編程序中使用數(shù)據(jù)組處理優(yōu)化方法。
(1)C程序
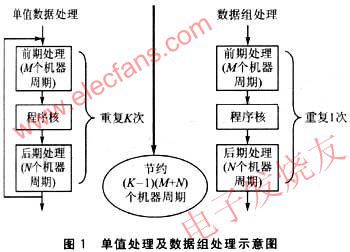
在C環(huán)境中開(kāi)發(fā)DSP程序,通常算法本身由匯編編寫,以便優(yōu)化實(shí)現(xiàn)。C主程序通過(guò)調(diào)用匯編實(shí)現(xiàn)的核心處理子程序來(lái)完成對(duì)數(shù)據(jù)的處理。核心處理子程序有兩種實(shí)現(xiàn)方法,一種是數(shù)組處理,另一種是單值處理,假設(shè)單值處理子程序的核心部分與數(shù)組處理子程序的核心部分所需機(jī)器周期相同,并且調(diào)用子程序的前期處理需M個(gè)機(jī)器周期,后期處理需要N個(gè)機(jī)器周期,如果子程序被調(diào)用K次,那么理想情況下,數(shù)據(jù)組處理可以節(jié)約(K-1)(M+N)個(gè)機(jī)器周期,如圖1所示。
(2)匯編程序
在匯編程序中實(shí)現(xiàn)數(shù)據(jù)組處理有多種方法,比如數(shù)組操作,數(shù)組讀入/寫出等。
1、數(shù)組操作。數(shù)組操作是將多個(gè)不同的短操作數(shù)裝入一個(gè)長(zhǎng)位數(shù)的寄存器,然后進(jìn)行運(yùn)算操作。比如,1個(gè)16位的寄存器可以裝入2個(gè)8位的來(lái)自A/D轉(zhuǎn)換器的數(shù)據(jù)。下面舉例說(shuō)明數(shù)據(jù)組處理在匯編程序中的應(yīng)用。
2、數(shù)組讀入寫出。這種方法是將多個(gè)短操作數(shù)合并為一個(gè)長(zhǎng)操作數(shù)后進(jìn)行讀入/寫出操作,如上面例子中的輸入/輸出部分。

1.2 數(shù)據(jù)存儲(chǔ)器交織
數(shù)據(jù)存儲(chǔ)器交織的目的是通過(guò)重新排列數(shù)據(jù)在存儲(chǔ)器中的位置,以使得程序讀寫數(shù)據(jù)的時(shí)間最短,比如有2個(gè)8位的復(fù)數(shù)x和y,一般情況下,復(fù)數(shù)將按下列順序存入內(nèi)存:real(x),image(x),real(y),image(y)。但如果想使得讀取復(fù)數(shù)的實(shí)部更容易,可以把數(shù)據(jù)重新排列如下:real(x),real(y),image(x),image(y),如圖2所示。

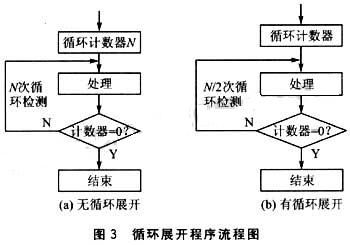
1.3 循環(huán)展開(kāi)
循環(huán)展開(kāi)是一種非常傳統(tǒng)的程序優(yōu)化方法,可以用于所有程序優(yōu)化中,循環(huán)展開(kāi)的目的是通過(guò)重復(fù)循環(huán)中的程序,減少循環(huán)次數(shù),從而減少循環(huán)判斷指令的執(zhí)行次數(shù),以此來(lái)降低程序執(zhí)行所需的機(jī)器周期,下面舉一個(gè)例子來(lái)說(shuō)明循環(huán)展開(kāi)在XC164CS單片機(jī)中的應(yīng)用。

1.4 指令流水線重排
指令流水線重排的意思是通過(guò)軟件程序中的指令重排來(lái)改變指令流水線,以此來(lái)排除由于硬件引起的指令堵塞,從而加快程序的運(yùn)行時(shí)間。這種優(yōu)化操作通常用在匯編程序中,指令流水線重排是一個(gè)一般的優(yōu)化原理,把這個(gè)原理用于不同類型的單片機(jī)可以導(dǎo)出不同的與單片機(jī)硬件相關(guān)的優(yōu)化方法。下面介紹的基于XC166單片機(jī)的優(yōu)化方法主要是應(yīng)用這個(gè)優(yōu)化原理得到的。
2 與芯片相關(guān)的優(yōu)化技術(shù)
2.1 XC166指令流水線
XC166單片機(jī)指令流水線共有7級(jí),前兩級(jí)為取指令流水線,后5級(jí)為執(zhí)行流水線,所有指令都必須經(jīng)過(guò)5級(jí)執(zhí)行流水線的每一級(jí)。
第1級(jí)--指令預(yù)取。這一級(jí)根據(jù)預(yù)測(cè)順序,把指令從程序管理單元(PMU)取出,取出的指令在跳轉(zhuǎn)檢測(cè)單元進(jìn)行前期處理,以檢測(cè)是否有跳轉(zhuǎn),預(yù)測(cè)邏輯決定是否接收轉(zhuǎn)移。
第2級(jí)--取指令。根據(jù)轉(zhuǎn)移預(yù)測(cè)規(guī)則計(jì)算出下一條被取指令的指針。對(duì)于零機(jī)器周期轉(zhuǎn)移,轉(zhuǎn)移合并單元先預(yù)處理,并將檢測(cè)到的轉(zhuǎn)移與正在執(zhí)行的指令結(jié)合起來(lái)。預(yù)取出的指令存在FIFO緩存器中,同時(shí),下一條要執(zhí)行的指令輸出FIFO緩存器,進(jìn)入執(zhí)行流水線。
第3級(jí)--譯碼。指令被譯碼,如需要,在間接尋址模式中,寄存器文件將被訪問(wèn),以讀取通用寄存器GPR。
第4級(jí)--尋址。計(jì)算所有操作數(shù)地址,對(duì)于所有隱含訪問(wèn)系統(tǒng)堆棧的指令,堆棧指針遞減或增加。
第5級(jí)--存儲(chǔ)。所有需要的操作數(shù)被取出。
第6級(jí)--執(zhí)行。使用已取出的操作數(shù)進(jìn)行MAC單元操作。對(duì)于非MAC單元指令,在這一級(jí)中,指令將由算術(shù)邏輯單元(ALU)執(zhí)行。條件標(biāo)志被更新,執(zhí)行所有直接對(duì)CPU特殊功能寄存器CPU_SFRs進(jìn)行寫操作的指令,在間接尋址時(shí),作為地址指針的GPRs自動(dòng)遞減或增加。
第7級(jí)--寫回。所有外部操作數(shù)以及剩余的,在內(nèi)部DPRAM空間內(nèi)的操作器被寫回。定位在內(nèi)部SRAM中的操作數(shù)進(jìn)入寫回緩沖區(qū)。
下面給出一個(gè)具體例子:


上面程序的指令流水線如表1所列,(Tn表示機(jī)器周期)
2.2 數(shù)據(jù)相關(guān)性排除
在XC166的CPU中,由于指令流水線的設(shè)計(jì)要求,在使用通用寄存器(GPRs)的指令之間存在一些數(shù)據(jù)相互依賴的情況,盡管XC166單片機(jī)已經(jīng)使用了專用硬件來(lái)檢測(cè)及解決數(shù)據(jù)相關(guān)性,但仍然有一些不可避免的數(shù)據(jù)相關(guān)性。在編程時(shí),可以充分利用數(shù)據(jù)相關(guān)性來(lái)達(dá)到程序優(yōu)化的目的,比如,在用GPR作為間接尋址指針時(shí),如果PGR中的地址值被改變,間接尋址操作必須等待2個(gè)機(jī)器指令周期后,才能使用GPR作為地址指針尋址。在這種情況下,可以在這2個(gè)等待機(jī)器周期內(nèi)插入2條其他單機(jī)器周期指令,充分利用這2個(gè)周期的等待時(shí)間以便程序更優(yōu)化。
下面舉一個(gè)例子:

另外一種數(shù)據(jù)相關(guān)性發(fā)生在間接尋址訪問(wèn)內(nèi)存時(shí),XC166單片機(jī)中的地址產(chǎn)生單元使用推測(cè)原理,在地址譯碼前,數(shù)據(jù)的讀取路經(jīng)將根據(jù)歷史記錄表中選出;在歷史記錄表中,每個(gè)GPR都有一個(gè)入口。這些入口記錄了用相應(yīng)GPR所訪問(wèn)的內(nèi)存空間情況。如果這種預(yù)測(cè)發(fā)生錯(cuò)誤,讀取操作必須重新開(kāi)始。
因此,如果用GPR作為間接尋址,GPR最好能指向相同內(nèi)存空間。如果更新后的GPR指向不同內(nèi)存空間,下一個(gè)操作將出現(xiàn)訪問(wèn)錯(cuò)誤,讀操作必須重復(fù),這就產(chǎn)生了指令流水線堵塞。例如:

2.3 內(nèi)存帶寬沖突排除
如果在流水線上的指令在同一時(shí)間訪問(wèn)同一內(nèi)存,就會(huì)發(fā)生內(nèi)存帶寬沖突,MAC單元的CoXXX指令是特別為實(shí)現(xiàn)DSP設(shè)計(jì)的。為了避免在DPRAM中發(fā)生帶寬沖突,CoXXX指令的其中一個(gè)操作數(shù)必須放在SRAM中,以保證在單個(gè)機(jī)器周期內(nèi)執(zhí)行MAC單元指令。例如:

2.4 指令重排
在用MAC單元指令編程時(shí),經(jīng)常要改變MAC單元的特殊功能寄存器,比如IDX0,IDX1、QX0、QX1、QR0以及QR1等,在XC166單片機(jī)中,有一些指令將會(huì)阻塞在譯碼階段,如果這些指令正好在一條修改特殊功能寄存器(SFR)指令之后執(zhí)行,這種阻塞將引起3個(gè)機(jī)器周期的延時(shí)。
這些指令包括:
◇使用長(zhǎng)地址模式的指令;
◇使用間接尋址的指令,除JMPS和CALLI外;
◇所有MAC單元指令(CoXXX指令)。
為了避免指令阻塞,在使用上述指令時(shí),如有阻塞情況發(fā)生,應(yīng)該重新重排指令,以消除延時(shí),例如:

3 結(jié)論
用于英飛凌XC166單片機(jī)的DSP優(yōu)化技術(shù)分為兩類:與硬件相關(guān)的優(yōu)化技術(shù)和獨(dú)立于硬件的優(yōu)化技術(shù)。獨(dú)立于硬件的優(yōu)化技術(shù)也可以用于其他的單片機(jī)或?qū)S脭?shù)字信號(hào)處理器。