
摘 要: 針對序列模式的幾個經典的算法的缺點,提出了一種基于時間約束序列模式的快速產生候選項的方法(TFEGC)。此算法不但避免了頻繁的掃描數據庫,還考慮了時間限制因素,避免了無用的候選序列的產生,提高了算法運行的時間效率。
關鍵詞: 序列模式挖掘;時間約束;候選項;快速產生
序列模式挖掘在很多領域都具有十分重要的意義,比如它可以根據分析顧客購買行為來決定商品的擺放位置,從而制定商場的營銷策劃。所以,近年來出現了很多序列模式挖掘的改進算法,目前提出算法中,有兩類比較典型:GSP[1]算法和采用分治策略來進行模式增長的PrefixSpan[2]算法。但是這兩種算法都存在一定的缺點。參考文獻[3]中提出的快速有效的產生候選項的FEGC算法,不需要多次掃描數據庫,且不需要在前一次迭代的基礎上來產生候選項,也不需對非頻繁項進行剪枝或修剪,能夠達到快速產生候選項的效果。但是,FEGC算法是針對數據庫總體的序列來產生候選項的,有些并不是有效的和用戶感興趣的序列,這在實際應用中就耗費了大量的時間和空間,如分析顧客的購買行為,就不需要將其一月份購買的產品和十二月份購買的產品放在一起進行研究比較。所以本文在FEGC算法的基礎上將時間限制因素加了進去,可稱之為TFEGC算法,本算法繼承了FEGC算法的優點,而且避免了不必要的、無用的一些候選項的產生,提高了算法的運行效率,且在序列結合的過程中,只需檢查uid、fid(t)以及s(t)的值,便可知道與哪些項進行結合,無須再進行檢驗。
1 相關算法介紹
GSP算法,即廣義序列模式算法,使用序列模式的向下封閉性,并采用多次掃描的候選產生-測試方法,它是由Srikant和Agrawal于1996年提出的。它的主要思想是利用序列模式的種子集,即前次掃描得來的序列模式來產生潛在的頻繁序列,即候選序列,每個候選序列都會比產生它的種子序列模式多包含一個項。直到一遍掃描不能產生新的序列模式或者新的候選序列時,算法終止。
PrefixSpan算法是前綴投影序列模式增長算法[4],此算法的特點是不需要產生候選項,算法思想是先找出各個頻繁項,然后分別產生它們所對應的投影數據庫,接著對各個投影數據庫進行挖掘,最后將前綴模式與后綴模式相連得到頻繁序列。此算法的缺點就在于可能會產生大量的投影數據庫,而且要掃描數據庫多次[3]。
FEGC算法的特點有:(1)Head、Body、Tail的引入,在一個交易序列中,處于Head的項在形成二序列時,只能作為二序列中的Head,處于Body的項在形成二序列時,既可以作為Head,也可以作為Tail;(2)Nid的引入,Nid的作用是用來規定在形成候選序列的過程中的2-序列的結合順序[1]。
2 TFEGC算法的理論和相關概念
對于給定的某個顧客的交易數據序列B={(Item,TID),…},其中Item表示交易的項,TID表示交易的時間,設I={(i1,t1),(i2,t2),…(in,tn)}是由n個不同的項組成的序列,它記錄了某個顧客在不同的時間購買的產品,然后根據時間限制將這個序列劃分成不同的子序列,再將這些子序列轉化為2-序列[5],最后以這些2-序列為基礎,找出所有的候選項。

2.2 公式的應用及td的引入
上面的三個公式都是為了解決利用TFEGC算法來求候選項時遇到的問題,它們所發揮的作用可通過下面的具體例子來進行詳細描述。
由圖1可知所有的2-序列過程,下面以子序列<bcde>產生的2-序列<bc>為例,具體過程如下:
(1)計算出uid=4-2=2,fid(c)=4-2=2,fid(d)=4-3=1,s(c)=2-1=1,s(d)=3-1=2;
(2)對于2-序列<bc>,因為s(c)=1,說明它只能與排在子序列<bcde>之后的第一個子序列產生的2-序列相結合,由圖1可知是子序列<cdef>產生的2-序列;又因為fid(c)=2,說明它只能與<cdef>產生的前兩個2-序列<cd>、<ce>相結合,生成<bcd>、<bce>;又因為s(d)=2、fid(d)=1,說明<bcd>還可以與排在子序列<bcde>之后的第二個子序列<def>產生的第一個2-序列<de>進行結合,生成<bcde>,e為子序列<bcde>的最后一項,不作考慮。

由上面的步驟(2)可知,雖然求得了s(c)的值,但是在算法的實現過程中,并不知道子序列<cdef>就是排在子序列<bcde>之后的第一個子序列,為了解決這個問題,引入了td的值,為節省存儲空間,可以用矩陣的形式來存儲td的值,如圖2所示。
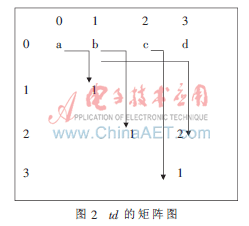
矩陣中沒有出現項e和項f,因為項f為序列的最后一項,所以它不會與任何二序列進行結合,由圖1知并沒有產生以e為首項的子序列,所以不會產生以e為首項的2-序列。
其中,[1,1]=1-0=1,表示排在以a為首字母的子序列之后的第一個子序列,是以b為首字母的子序列;[2,2]=2-1=1,表示排在以b為首字母的子序列之后的第一個序列,是以c為首字母的子序列,依此類推。
所以,當算出s(t)的值時,只需比較其與td的值,當s(t)=td的值時,則此序列就是所要結合的2-序列。
3 TFEGC算法
3.1 算法思想
本算法一共有四大步,第一步是根據時間限制將原序列劃分為多個子序列;第二步是將得到的子序列轉化為2-序列;第三步是根據uid、fid(t)和s(t)的值將2-序列進行結合,從而得到所有的候選項;第四步根據最小支持度minsup得到頻繁項集。
從上所述可以看出,此算法的主要特點有:(1)加入了時間限制因素;(2)只需要掃描數據庫一次,節省了算法的運行時間;(3)引入了uid、fid(t)、s(t),使之在形成n-序列的過程中,能夠準確地找到要結合的2-序列,不需要掃描所有子序列產生的二序列,提高了算法的時間效率。
3.2 TFEGC核心算法描述
2-序列結合的算法如下:
for all I∈DB{ //I為滿足時間限制的子序列
l=strlen(I);
uid=l-2;
for(n is smaller thanl ){
if(in∈I and n≠1 and n≠1)
{ //in不能為首尾兩項
s(in)=n-1;
fid(in)=l-n;}
}
for(scan the Matrix Chart of td){//掃描矩陣td
if(td==s(in)){
record the item r and
record those 2-sequence se whose first item is r;}
//r用來存放首項,se用來
//存放以其為首項形成的2-序列
}
for all tn∈se{
if(tn.index==fid(in)){//找到所要結合的2-序列
in+tn;}//2-序列in和2-序列tn相結合
}
}
3.3 算法舉例
為了進一步描述TFEGC算法,以圖1中的子序列<abc>產生的第一個2-序列<ab>為例,求以這個2-序列為基礎所形成的候選項過程,如圖3所示。

4 實驗結果
算法實驗環境為PentiumⅣ3.0 GHz雙核 PC機器,內存為1 GB,Windows XP操作系統,采用C++語言在VC編程環境下實現。實驗測試數據采用IBM數據生成器,該生成器是目前數據挖掘相關研究中使用廣泛和權威的生成器,可以通過設置參數生成不同特性的數據集,具體參數含義如表1所示。
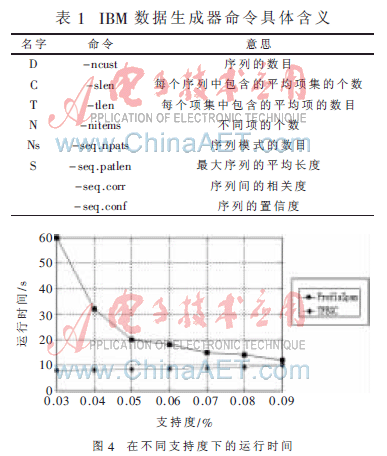
PrefixSpan算法和TFEGC算法在不同的支持度下的運行時間如圖4所示,從結果可以看出文中提出的方法優于PrefixSpan算法,因為TFEGC算法只需要掃描數據庫一次,而且由于uid、fid(t)以及s(t)的引入,避免了一些無用序列的產生,大大減少了運行時間。
圖5所示的是FEGC和TFEGC在不同數量的顧客下算法的運行時間,從中也可以看出TFEGC算法的運行時間少于FEGC算法的運行時間。這是因為在二序列的結合過程中,TFEGC不需要逐個掃描其他的二序列,只需查看uid、fid(t)以及s(t)的值就可以判斷應該與哪些二序列進行結合,而且生成的用戶不感興趣的序列也大大減少了。因為加入了時間的限制,所以根據支持度來提取頻繁序列的時間也就相應地減少了。

本文提出的算法,可由用戶自己設定時間限制來查找頻繁序列,也可以用來處理不同數量的客戶群,所以具有一定的靈活性。又因為其只掃描數據庫一次,而且二序列的結合也具有一定的明確性,所以在時間效率上具有一定的優越性[6]。
參考文獻
[1] SRIKANT R,AGRAWAL R.Mining sequential patterns:generalizations and performance improvements[C].Proc.of Int’l Conf.on Extending Database Technology,1996:3-17.
[2] PEI J,HAN J,Mortazavi-Asl B,et al.Prefixspan: mining sequential patterns efficiently by prefix-projected pattern growth[C].Proc.of Int.Conf.on Data Eng. (ICDE’01),2001:215-224.
[3] Liao Weicheng,Yang Donlin,Wu Jungpin,et al.Fast and effective generation of candidate-sequences for sequential pattern mining[C].2009 Fifth International Joint Conference on INC,IMS and IDC,2009:2006-2009.
[4] 趙暢,楊冬青,唐世渭.Web日志序列模式挖掘[J].計算機應用,2000,9(20):13-16.
[5] 連一峰,戴英俠,王航.基于模式挖掘的用戶行為異常檢測[J].計算機學報,2002,25(3):325-329.
[6] 吉根林,帥克,孫志揮.數據挖掘技術及其應用[J].南京師范大學學報(自然科學版),2000,23(2):25-27.