
摘 要: 目前基于內容的發布/訂閱系統得到了廣泛的應用,而事件和訂閱的匹配算法是其中的一個關鍵問題。提出了一種高效的匹配算法,首先根據謂詞類型和名稱的不同建立若干訂閱樹,建立一個索引結構管理這些樹。匹配時,根據事件的類型和名稱在對應的樹中進行搜索。實驗證明該算法具有較好的匹配性能。
關鍵詞: 發布/訂閱;匹配算法;多維索引
發布/訂閱系統是一種用于信息交互的中間件系統,它將信息的發布者與訂閱者聯系在一起。發布者只負責發布信息給中間件,訂閱者也只向中間件訂閱自己感興趣的信息,信息具體的發布和傳送則由發布/訂閱系統負責,這樣大大降低了系統的耦合性,使通信更加靈活,符合分布式系統的需求,所以在分布式系統中得到了廣泛的應用。
在基于內容的發布/訂閱系統中,信息由事件來表示,訂閱者可以通過訂閱事件來獲取信息。一個事件可以表示為一些屬性的集合,而訂閱則可以表示為一些謂詞的集合。訂閱者可以通過指定其感興趣的謂詞來靈活地訂閱事件。相對于基于主題的發布/訂閱系統,基于內容的發布/訂閱系統中訂閱的表達能力得到了很大的提高,但是同時系統中的訂閱數目也大大增加,匹配的復雜度大大提高,必須有一個高效的算法來實現訂閱和事件的快速匹配[1]。匹配算法的基本思想是盡量優化訂閱結構,減少匹配時訂閱條件中重復部分的判斷,提高匹配效率。
1 相關研究
目前相關的研究已經提出了很多比較有代表性的算法[2-6]。Aguilera等提出了基于搜索樹的算法[4],這種方法建立一棵搜索樹,每個非葉子節點表示一個對訂閱條件的測試,每條邊代表測試結果,每個葉子節點表示一個訂閱條件。當匹配一個事件時,如果按照樹的某一路徑可以從樹根到達一個葉子節點,說明該葉子節點代表的訂閱與這個事件相匹配。這種方法中相同的訂閱條件只需要測試一次,但是節點間的耦合性較高,相應地,維護樹的代價也比較高。
計數法的思想是測試所有謂詞,建立一個表保存謂詞和訂閱的映射關系,即謂詞被哪些訂閱滿足。匹配時,遍歷這個表找出滿足一個訂閱的謂詞數目,將之與這個訂閱包含的謂詞數目進行比較,如果相等,則說明事件與訂閱相匹配。計數法雖然避免了一個謂詞被多次測試,但是它總會對訂閱中所有的謂詞進行測試,而實際上當一個謂詞無法匹配時,其他的測試都不需要繼續進行。
2 匹配算法
本文提出的方法借鑒了基于搜索樹的方法,學習了其中的優點,并針對其中存在的缺點進行了改進。搜索樹的方法將所有謂詞添加到一棵樹中,樹的深度和耦合度比較大,不利于訂閱樹的維護。所以本文方法中修改了構造訂閱樹的方法,按照謂詞類型和名稱的不同創建若干訂閱樹,將不同的謂詞放到不同的樹中,減少了耦合度。為了便于管理這些搜索樹,建立了一個索引結構,根據謂詞類型和名稱的不同可以快速找到對應的訂閱樹。
2.1 訂閱模型和事件模型
在基于內容的發布/訂閱系統中,為了能讓訂閱者快速、準確地指定所需信息,訂閱者要通過一定的訂閱模型來訂閱信息,發布者也要通過一定的事件模型來發布數據,所以在提出匹配算法之前,首先定義如下的訂閱模型和事件模型:
(1)事件
事件包含了一些發布者發布的數據,可以定義為一些屬性的集合。屬性是最小的數據,可以表示為一個數據類型、屬性名稱和屬性值組成的三元組,即 Attribute:=。屬性的數據類型定義有數值類型和字符串型。事件可以表示為{A1,A2,…,An},即Event:=∪Attribute。
例如事件E1={(int,x,10),(string,s,“teacher”)}包含兩個屬性A1=(int,x,10)和A2=(string,s,“teacher”)。
(2)訂閱
一個訂閱表示了一個訂閱者所感興趣的數據,可以定義為一些謂詞的集合。謂詞是對一個屬性的測試結果,可以表示為一個數據類型、屬性名稱、測試操作符和匹配值組成的四元組,即Predicate:=(type,name,operator,value)。謂詞的測試操作符(operator)對應的數值型定義有=、>、<、>=、<=和!=,對應字符串型定義有=、!=和*=(包含)。訂閱可以表示為{P1,P2,…,Pn},即Subscription:=∪Predicate。
例如訂閱S1={(int,x,>,10),(string,s,!=,“student”)},包含兩個謂詞P1=(int,x,>,10)和P2=(string,s,=,“student”)。
定義1. 屬性a(typea,namea,valuea)與謂詞p(typep,namep,operatorp,valuep)匹配,則要滿足(typea=typep)∧(namea=namep)∧(operatorp(valuea,valuep)=true)。
定義2. 事件e與訂閱s匹配,則對于s中的每個謂詞p,e中至少存在一個屬性a與p匹配。
定義3. 謂詞p1與謂詞p2間存在覆蓋關系,則對任意一個屬性a,如果它和p2匹配,則它也一定和p1匹配。
定義4. 謂詞p1與謂詞p2沖突,則當p1成立時,p2一定不成立。
2.2 訂閱樹的構造
在構造訂閱樹之前,增加一個對訂閱集合預處理的步驟。這是因為在一個訂閱中可能存在著沖突和重復的謂詞,在訂閱和匹配開始前就進行處理可以付出最小的代價。進行預處理時要遍歷所有訂閱,對于謂詞存在沖突的訂閱,由于一定不存在事件能與之匹配,所以不需要將之添加到訂閱樹中;對于謂詞間存在覆蓋關系的訂閱,只保留最大的謂詞,這樣可以減少訂閱中謂詞的重復。
接下來根據上一步經過預處理的訂閱集合來創建若干訂閱樹,將類型和名稱相同的謂詞生成的節點添加到一棵訂閱樹中。訂閱樹中的每個節點存儲了一個謂詞和包含這個謂詞的訂閱的集合。為了便于在訂閱樹中進行匹配,分別以謂詞的類型、名稱和操作符為鍵建立一個多級索引結構來管理所有的訂閱樹,如圖1所示,將指向每棵訂閱樹根節點的指針對應存儲在索引結構中,這樣當需要匹配一個事件的屬性時就能根據屬性的類型和名稱進行快速定位。
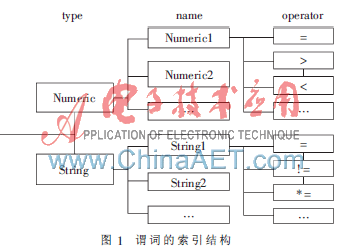
構建訂閱樹時要考慮到謂詞間的覆蓋關系,讓父節點的謂詞覆蓋子節點的謂詞,這樣進行事件匹配時,如果父節點的謂詞與事件的對應屬性不匹配,則屬性與子節點的謂詞也一定不匹配,加快了匹配的速度。
在訂閱樹中增加節點時,先通過索引結構找到對應的樹,然后在樹中查找這樣一個節點:這個節點覆蓋了新增加的節點,而它的子節點都不覆蓋新節點,然后將新節點插入到這個節點和它的子節點之間,新節點的訂閱集合也要添加相應的訂閱者。
在訂閱樹中刪除節點時,先通過索引結構找到對應的樹,從根節點遍歷樹,如果找到一個節點被要刪除的節點覆蓋,則將對應的訂閱者從以這個節點為根的樹中的所有節點的訂閱集合中刪除,如果刪除后某個節點的訂閱集合為空,則刪除該節點。
下面給出了構建訂閱樹的算法偽代碼:
ADD-SUBSCRIPTION (sub)
for each predicate Pi in sub
do find root node of the corresponding tree by the
type and name of Pi
if the tree doesn’t exist
create a new tree
ADD-PREDICATE (rooti,Pi)
ADD-PREDICATE (node, p)
if the predicate of node covers p
for each child of node childi
do if the predicate of childi covers p
then ADD-PREDICATE (childi, p)
else if p covers the predicate of childi
then insert p between node and childi
else save p as a child of node
2.3 事件匹配
由于訂閱樹的構造方法的改變,事件匹配的方法也有所不同,采用了先找出所有不匹配的訂閱,然后得到匹配的訂閱方法。匹配一個事件時,先對所有謂詞進行測試,對事件中的每個屬性,依次查找類型和名稱對應的訂閱樹。如果找到了相應的訂閱樹,則用這個屬性測試訂閱樹中所有的節點。在測試的過程中,如果一個節點測試失敗,則記錄下這個節點的訂閱者和以這個節點為根的子樹中所有節點的訂閱者。測試完成后,在訂閱集合中剔除所有不匹配的訂閱,就能找出所有與當前事件匹配的訂閱。
3 實驗分析
實驗采用的計算機采用雙核Core2、主頻為1.6 GHz的CPU,2 GB的DDR2內存,Windows XP系統,算法的實現采用Visual Studio 2008平臺,C++語言。編寫了一個訂閱產生器和事件產生器來產生實驗樣本,每個實驗結果為10次運行的平均值。每個訂閱的形式如(numeric1>10,numeric2 !=8,string1 *=“student”),每個事件的形式如(int1=12,int3=200,string2=“teacher”)。
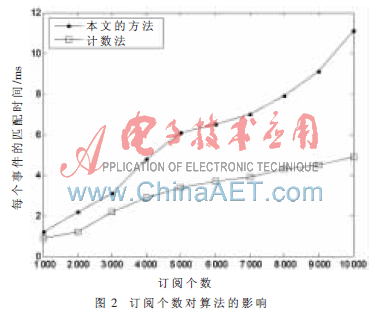
實驗一 測試訂閱數量對匹配速度的影響。首先向系統中添加訂閱,訂閱數目變化范圍為1 000~10 000個,每個訂閱包含5~10個謂詞;然后隨機生成一個事件,這個事件包含的屬性個數為20,測試匹配這個事件所需的時間。實驗結果如圖2所示。
實驗二 測試事件屬性個數對匹配速度的影響。向系統中添加5 000個訂閱,每個訂閱包含5~10個謂詞,隨機生成事件,事件的屬性個數變化范圍為5~20個,測試匹配事件所需的時間。實驗結果如圖3所示。
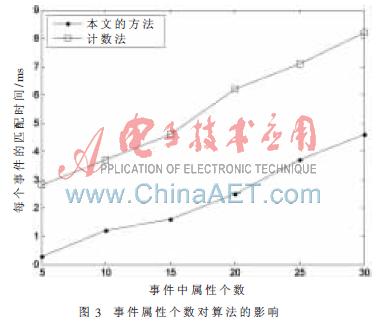
從上面的實驗結果可以看出,本文提出的算法在匹配效率上相對于計數法和基于匹配樹的算法有了較大的提高。當事件的屬性個數相同而系統訂閱數不斷增加時,和系統中訂閱數目相同而事件包含的屬性個數不斷增長時,這種算法明顯表現出了它的高效性。
近年來基于內容的發布/訂閱系統逐漸獲得了越來越廣泛的應用。本文針對基于內容的發布/訂閱系統中的事件與訂閱的匹配,提出了一種匹配算法。這種算法利用一個多級索引結構來管理不同類型和名稱謂詞,提高了謂詞的匹配速度,而且充分考慮了謂詞間的覆蓋關系,減少了匹配次數。最后通過實驗證明了這種算法的正確性和高效性。未來可以對算法的覆蓋關系、訂閱樹的結構等進行更一步的改進。
參考文獻
[1] 馬建剛,黃濤.面向大規模分布式計算發布訂閱系統核心技術[J].軟件學報,2006,17(1):134-147.
[2] KALE S,HAZAN E,CAO F,et al.Analysis and algorithms for content-based event matching[C].In proceedings of ICDCS Workshops,2005:363-369.
[3] FABRET F,LLIRBAT F,PEREIRA J,et al.Efficient matching for content-based publish/subscribe systems[C]. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles,2003,37(5):29-43.
[4] AGUILERA M K,STORM R E,STURMAN D C,et al. Matching events in a content-based subscription system[C]. In proceedings of the 18th ACM Symposium on Principles of Distributed Computing,1999:53-61.
[5] 齊鳳亮,金蓓弘.發布/訂閱系統中的原子訂閱管理和匹配[J].軟件學報,2009,36(12):111-114.
[6] 薛濤,馮博琴.基于內容的發布訂閱系統中快速匹配算法的研究[J].小型微型計算機系統,2006,27(3):529-535.