
摘 要: 針對滿足語音端點檢測的實時性要求,設計了一種基于FPGA的語音端點檢測系統。介紹了語音端點檢測的整個過程和一種改進的基于能量的端點檢測算法,以及如何用FPGA實現該算法。設計中運用DSP Builder工具,移位法、查表法和有限狀態機法,簡化了硬件設計的同時也提高了運算速度。實驗結果分析表明,此系統能準確地判斷語音信號的起點和終點。
關鍵詞: 端點檢測;FPGA;DSP Builder
語音端點檢測就是從背景噪聲中找到語音的起點和終點,其目標是要在一段輸入信號中將語音信號同其他信號(如背景噪聲)分離并且準確地判斷出語音的端點。研究表明,即使在安靜的環境中,一半以上的語音識別系統識別錯誤來自端點檢測。因此,端點檢測的重要性不容忽視,尤其在噪聲環境下語音的端點檢測,它的準確性很大程度上直接影響著后續的工作能否有效進行[1]。
當前語音識別系統大多以ARM、DSP為設計核心,其設計費用高、缺乏靈活性、開發周期長,而且很難滿足高速的系統要求。在對語音端點檢測算法的研究中,提出了諸如基于能量、過零率、LPC預測殘差等多種算法[2],但這些方法大部分都是基于計算機軟件的,不適合進行硬件開發[3]。
FPGA具有功耗低、體積小、速度快等優點,可以滿足語音識別系統的實時性要求。本文嘗試用FPGA實現語音端點檢測,對常用的Lawrence Rabiner端點檢測法進行改進,用純硬件的方法實現語音端點檢測,并以“長沙”等詞和短語為例,驗證其準確性和可行性。
1 FPGA實現語音端點檢測基本原理
主要由四個部分完成:預加重、分幀、加窗和端點判斷,FPGA實現方法同樣要經過這四個步驟。
1.1 預加重
語音信號的平均功率譜由于受聲門激勵和口鼻輻射的影響,高頻端大約在800 Hz以上按6 dB/Oct(倍頻程)衰減,這樣語音信號的頻譜中,頻率越高相應的成分越少,因而要得到高頻部分的頻率比低頻部分更困難。所以,對語音信號進行分析之前,要對語音信號加以提升,使語音信號的短時頻譜變得更為平坦,從而便于進行頻譜分析和聲道參數分析。提升的方法有模擬電路法和數字電路法,本設計主要采用數字電路法。一般的數字電路法用一階的數字濾波器來實現:

式(2)只有移位和加減運算,即用簡單的移位來取代復雜的小數乘法運算,從而可以方便地用FPGA實現。
1.2 分幀加窗
分幀處理即將預加重后的語音信號分成多段進行分析,即從原始語音序列中分解出一個新的依賴于時間的序列,便于描述語音信號特征。語音信號具有時變特性,但在相當短的時間范圍內,其特性基本保持不變,從而可以進行分段分析。假設語音信號在10 ms~30 ms內平穩,就可以以此時間段為單位將語音信號分ms段進行分析,其中每一段稱為一“幀”,每一幀的長度叫幀長。為了使幀與幀之間保持連續平滑過渡,分幀一般采用交疊分段的方法,前一幀和后一幀的交疊部分稱為幀移。幀移與幀長的比值一般取為0~1/2。為便于語音識別系統中特征的提取,取2n為幀長。本文語音信號的采樣頻率為16 kHz,取幀長為256(16 ms),幀移為128。
分幀的FPGA實現。其關鍵就是解決幀移的疊加問題。可以用兩個FIFO(F1和F2)來實現,具體過程為:先向F1寫入128個數;讀取F1中的數得到這幀前128個數,同時將F1中的數寫入F2中;F1的數讀完時F2也已寫完,此時再讀取F2中的數得到這幀的后128個數(這時就得到了一幀的語音信號),在讀取F2中數據的同時向F1寫入下一幀的數據,這樣一直循環就完成了語音的分幀。
分幀后幀之間重新拼接處語音信號的頻譜特性和原來相比會有差異。為了使語音信號在幀之間重新拼接處的頻譜特性與原來更加接近,就要進行加窗處理。在語音信號處理中常用的窗函數是矩形窗和漢明窗[5]。它們的表達式如下(其中N為幀長):
矩形窗:
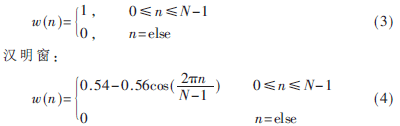
矩形窗的主瓣寬度較小,因而具有較高的頻率分辨率;但它的旁瓣峰值較大,因此其頻譜泄露比較嚴重。相比較而言,雖然漢明窗主瓣寬度較矩形窗大一倍,但是它的旁瓣衰減較大,因而具有更平滑的低通特性,能夠在較高程度上反映短時語音信號的頻譜特性,所以本文采用漢明窗。
加窗的FPGA實現。加窗就是用分幀后的數據乘以窗函數。在FPGA的實現上加漢明窗的過程難點是小數余弦乘法運算,如果用算法來實現運算會比較慢。這里考慮到N比較小,可以采用查表法實現加窗處理。查表法就是將窗函數的各個值存在ROM里面,依次查找。這里用DSP Builder工具生成窗函數的各個值,因為Altera公司開發的DSP Builder工具有很強的數字信號處理功能,能很好地完成窗函數的運算。具體操作步驟為:在Matlab中打開simulink工具并打開Altera DSP Builder Blockset工具箱,然后新建“.mdl”文件,在工具箱中找到相應的模塊并連接。在“hamming_table”模塊的“Matlab Array”中輸入“0.54-0.56*cos([0:2*pi/255:2*pi])”。然后編譯、綜合,系統就會自動生成查表法要用到的“.hex”文件。
1.3 端點判斷
端點判斷是整個端點檢測中最重要的部分,也是計算量最大的部分。所以算法的選擇非常重要,本文用算法是根據Lawrence Rabiner端點檢測法改進而來的。先介紹下Lawrence Rabiner端點檢測法,這種方法以過零率ZRC和能量E為特征來檢測起止點,具體方法為:
該算法是以基于能量的起止點算法。根據發音剛開始前已知為“靜”態的的連續10幀內的數據,計算能量閾值T1(低能量閾值)及T2(高能量閾值)。開始計算前10幀每幀的能量,設其最大值稱之為MX,最小值為MN,過零率閾值為ZCT,則有:
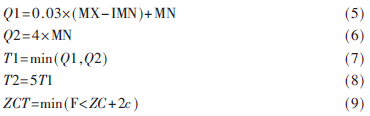
其中,F為固定值,一般為25,ZC和c分別為最初10幀過零率的均值和標準差。先根據T1、T2算得初始起點BN(起點幀號)。方法為:從第11幀開始,逐次比較每幀的平均幅度,BN為能量超過T1的第一幀的幀號。但若后續幀的能量在尚未超過T2之前又降到T1之下,則原BN不作為初始起點,改記下一個能量超過了T1的幀的幀號為BN,依此類推,在找到第一個能量超過T2的幀時停止比較。當BN確定后,從BN幀向(BN-25)幀搜索,依次比較各幀的過零率,若有3幀以上的ZCR>ZCT,則將起點BN定為滿足ZCR>ZCT的最前幀的幀號,否則即以BN為起點。這種起點檢測法也稱雙門限前端檢測算法。語音結束點EN(結束點幀號)的檢測方法與檢測起點相同,從后向前搜索,找第一個能量低于T1且其前向幀的能量在超出T2前沒有下降到T1以下的幀的幀號,記為EN,隨后根據過零率向(EN=25)幀搜索,若有3幀以上的ZCR≥ZCT,則將結束點EN定為滿足ZCR≥ZCT的最后幀的幀號,否則即以EN作為結束點。
這種算法硬件實現起來比較復雜,而且速度慢,所以要對算法進行改進。改進后的算法為:超過高門限可以用于確定語音的開始,低門限用于確定語音的終點。超過高門限未必就是語音的開始,有時候噪聲的能量也可能相當大從而超過高門限,但是噪聲一般持續時間比較短,可以用超過高門限持續時間來決定是噪聲還是語音開始。當高門限已經確定語音開始后,再利用低門限來確定語音的結束點。低于低門限未必就是語音的結束,有時候語音信號的能量也可能低于低門限,但是語音信號低于低門限的時間不可能很長,可以用低過低門限的時間來判斷語音的結束點。這樣起止點的檢查,就減少了過零率的判斷和前10幀過零率均值和標準差的計算。所以這個算法門限值的選擇對語音端點檢測的影響比較大,本設計的門限值是根據Lawrence Rabiner端點檢測法并通過大量實驗得來,計算式如式(10)和式(11)。其中,AE為前14幀的平均能量、T1是低門限、T2是高門限。
T1=1.5AE(10)
T2=2T1(11)
在FPGA設計中,狀態機的設計方法是最廣泛的設計方法之一,FSM(有限狀態機)及其設計技術是實用數字系統設計的重要組成部分,是高效率、高可靠邏輯控制的重要途徑。而改進后的算法可以把整個端點判斷過程分為三個狀態,可以利用狀態機來完成FPGA的設計。狀態轉換圖如圖1所示。S0、S1、S2是三個狀態;E為幀能量;T1、T2分別是低門限和高門限;C1是在狀態S1中T2>E≥T1的幀數;C2是在狀態S1中T2≤E的幀數;C3是在狀態S2中T1>E的幀數。

具體判斷過程為:(1)在S0狀態下,E<T2時狀態不變;E≥T1時進入S1狀態。(2)在S1狀態下,E<T1時狀態回到S0; T1≤E<T2狀態不變,同時C1加1。E≥T2時狀態不變,同時C2加1;C2等于10時進入S2狀態并確定語音起點。(3)在S2狀態下,E≥T1時狀態不變;E<T1時狀態不變,同時C3加1;C3等于4時狀態回到S0并確定語音結束點。
2 實驗結果
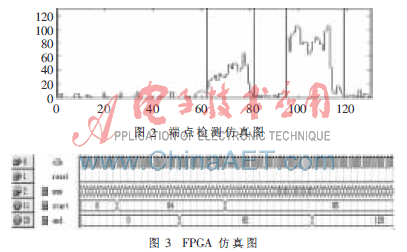
實驗時的聲音樣本采用電腦聲卡采集(16 kHz,8 bit)的“wav“文件, 并對常用的詞語進行實驗。圖2是詞“長沙”在Matlab上的端點檢測仿真結果圖,其中橫坐標代表幀號、縱坐標代表幀能量。兩個字的語音段分別是64~82幀和95~120幀。圖3是詞“長沙”在QuartusⅡ上仿真的結果圖,其中num代表每幀的幀號,start代表語音開始的幀號,end代表語音結束的幀號。從圖1、圖2可以看出詞“長沙”的端點檢查仿真結果在Quartus Ⅱ上的和Matlab上是一致的,從圖中可以看出改進后的端點檢測方法檢測效果非常好。
本文在加窗的過程中合理地運用了DSP Builder工具,簡化了硬件的設計,同時也加快了處理速度,是一種很值得借鑒的FPGA加窗方法。在端點判斷的算法上,用改進的Lawrence Rabiner端點檢測法,對算法門限的計算和起止點判斷做了改進,并用有限狀態機實現了FPGA的設計,實驗證明該算法在低信噪比的情況下能準確地找到語音信號的起止點。與其他一些端點檢測方法相比,該算法更加簡單、穩定,所需的存儲空間小,是一種理想的硬件端點檢查方法,對語音識別系統的開發和設計有一定的參考價值。
參考文獻
[1] 吳亮春,潘世永.一種語音信號端點檢測方法的研究[J]. 計算機與信息技術,2009,12(3):14-18.
[2] 楊行峻,遲惠生.語音信號數字處理[M].北京:電子工業出版社,1995.
[3] 何方,朱杰,郁樺,等.一種語音信號端點檢測方法及其在DSP上的實現[J].微型電腦應用,2002,18(5):48-50.
[4] HAN Wei,CHAN Cheong Fat,CHOY Chiu Sing.An efficient MFCC extraction method in speech recognition[J]. IEEE International Symposium on,2006:145-148.
[5] 張雄偉,陳亮,楊吉斌.現代語音信號處理技術及應用[M].北京:機械工業出版社,2003.